Stanford University — Interactive Perception & Robot Learning Lab
Robotics Researcher · March 2025 – present · Mentors: Prof. Jeannette Bohg, Dr. Cherie Ho
Developing a persistent, object-centric memory system linking RGB-D perception with adaptive task planning for mobile manipulators. Built a real-time scene-graph that synchronizes perception, action, and memory, updating as the robot explores and interacts with its environment. Leveraged VLMs grounded with physical awareness to predict object affordances and choose appropriate motion primitives for interaction. Testing in Mujoco/IsaacSim and real-world experiments with TidyBot.
Previously built a dexterous grasp evaluation pipeline using 3D Gaussian Splatting. Designed custom VQ-VAE architecture to compress 3DGS into latent codes and trained a multi-headed evaluator predicting grasp success, collisions, and stability, achieving 95.1% grasp success rate in simulation, surpassing BPS/NeRF baselines.
Columbia University — Speech Lab
NLP Researcher · May 2023 – Dec 2023 · Mentor: Prof. Julia Hirschberg
Built an emotion-aware conversational AI system combining ASR, prosodic features, and LLM
reasoning to detect sudden emotion shifts from neutral or happy to sad or anger. Multimodal fusion of transcripts,
audio embeddings, and dialogue context. Trained on 150+ IEMOCAP videos (~10GB), improving accuracy from ~40% to 78%.
Columbia University — Robot Learning
Independent Researcher · Nov 2022 – Aug 2023 · Mentor: Prof. Shuran Song
Led a team of 4 researchers to build zero-shot learning framework that assesses step-by-step task execution
for long-horizon tasks. Algorithm describes predicted step outcome with LLM, evaluates video data against language
outcome description with VLM, and assesses incremental progress with custom scoring metric. Achieved ~95% accuracy
across diverse household and kitchen tasks. First-author publication at International Conference for Robotics and Computer Vision
(ICRCV) 2023.
Columbia University — ML & Forecasting
Student Researcher · Oct 2023 – July 2024 · Mentor: Prof. Michelle Levine
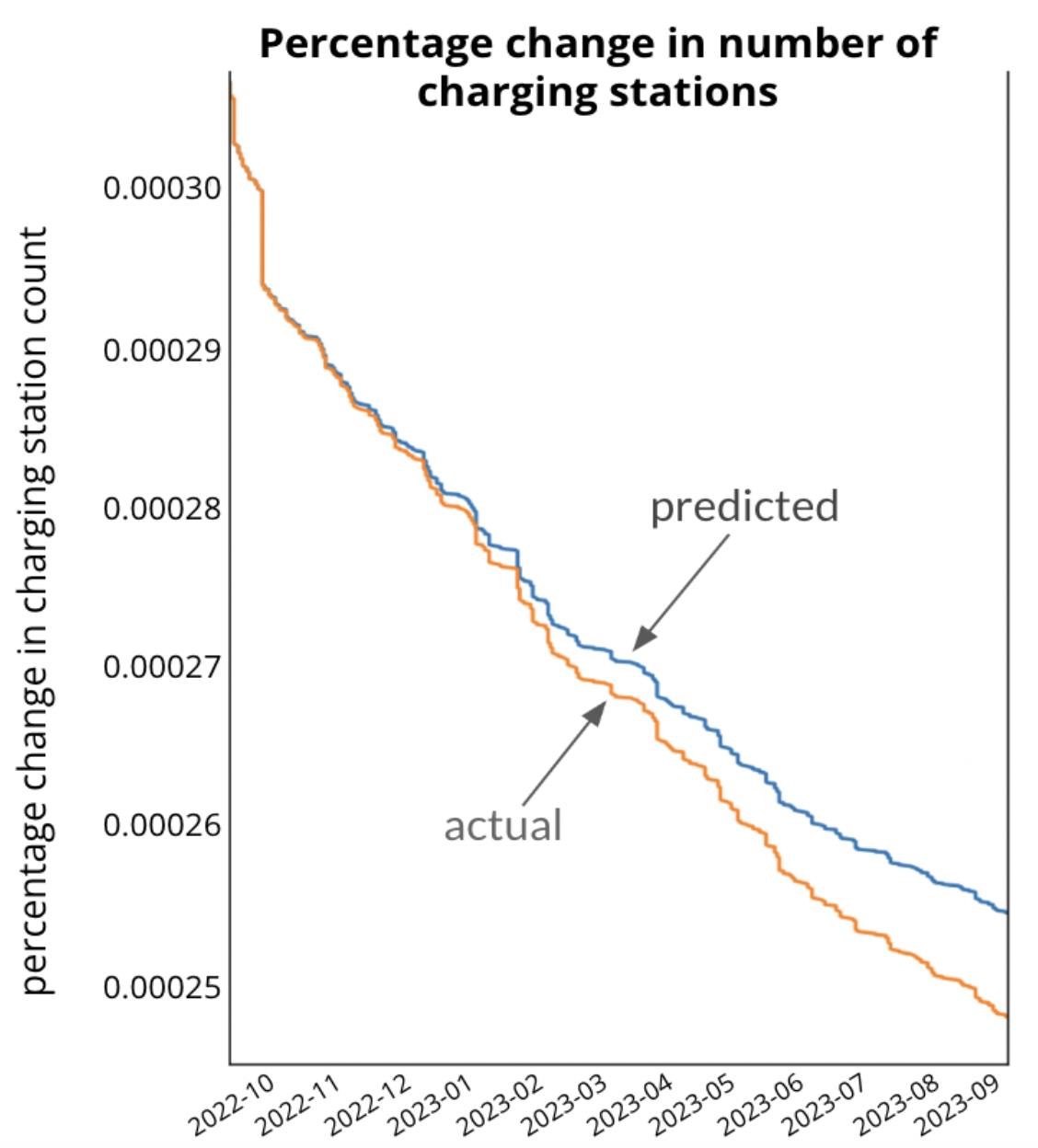
Built vector autoregression models to forecast EV adoption using policy incentives and
charging infrastructure data. Produced a first-author publication at ITISE 2024.
Columbia University — Creative Machines Lab
Undergraduate Researcher · Sept 2022 – Dec 2022 · Mentor: Prof. Hod Lipson
Designed a NeRF-inspired model that learns robot kinematics from single-view video by predicting
occupancy from 3D coordinates and joint angles. Used PyBullet-derived camera intrinsics to
reconstruct 3D geometry from 2D single-view data.